Quality Control of Open Code
In principle, Open Code should be well-structured and "readable", in other words accompanied by comprehensive and easy-to-understand documentation: What does the code do? How can I execute it? How can I reuse it?
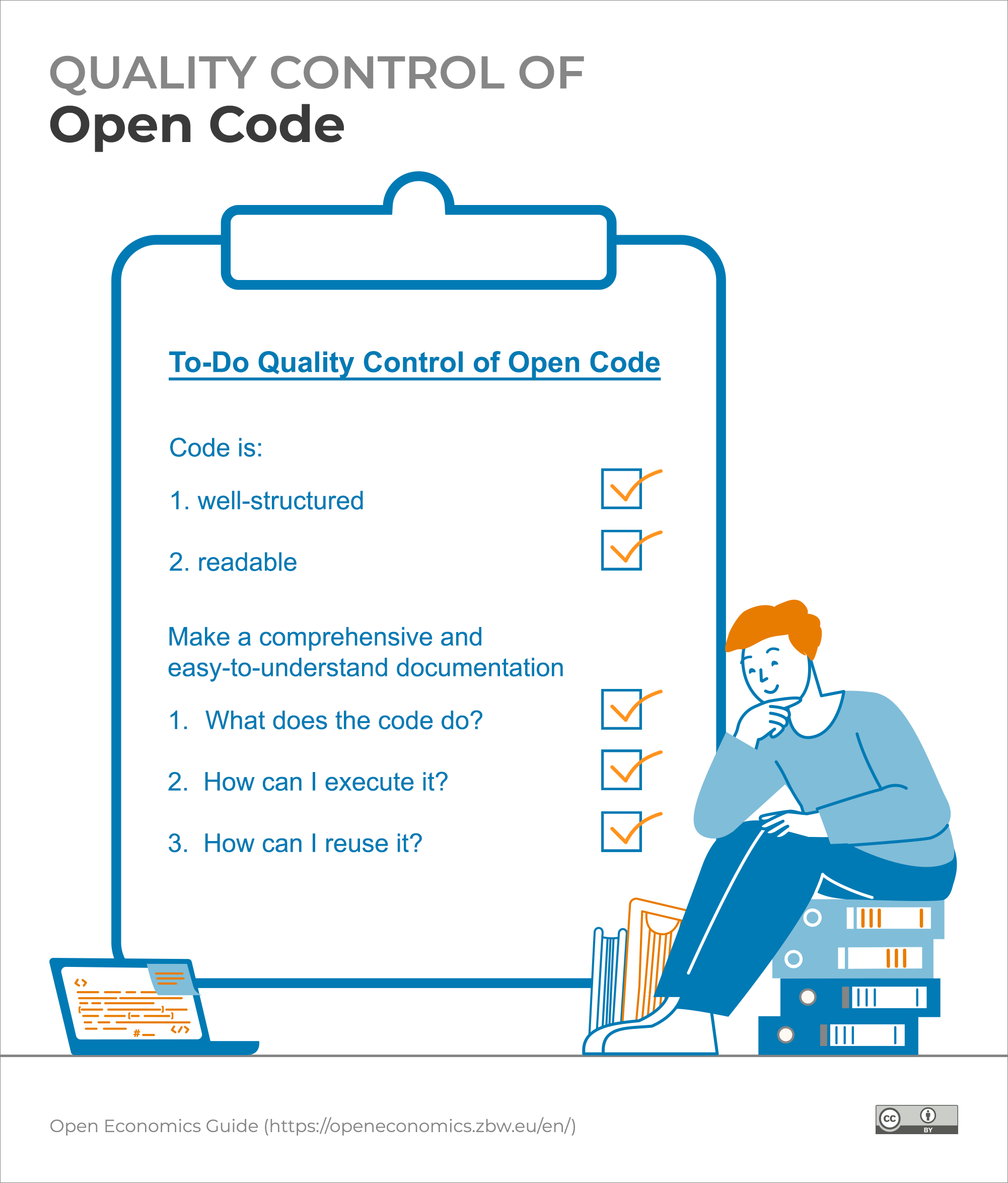
This form of quality assurance for Open Code also plays a role in scientific peer review to some extent. There are an increasing number of journals that apply the Data and Code Availability Standard to ensure the availability of the data and code on which a publication is based. Their fulfilment is then also part of the review or a prerequisite for submission. Some journals of the American Economic Association implement this standard and check the so-called "computational reproducibility" as part of the review process. This involves attempting to execute the code and, if successful, checking whether the result data is identical to that of the authors. This requires appropriate documentation. However, the code itself or the source code is not viewed in detail and checked for errors, for example. This means that a so-called "code review" does not take place.
Tips:
- Guide "Software Deposit: How to review a software deposit" from Michael Jackson (The Software Sustainability Institute)
- The Turing Way offers further information, including on code quality